
Lia
@liareplaysbk
· 09:28 PM · Oct 27, 2020
Permalink
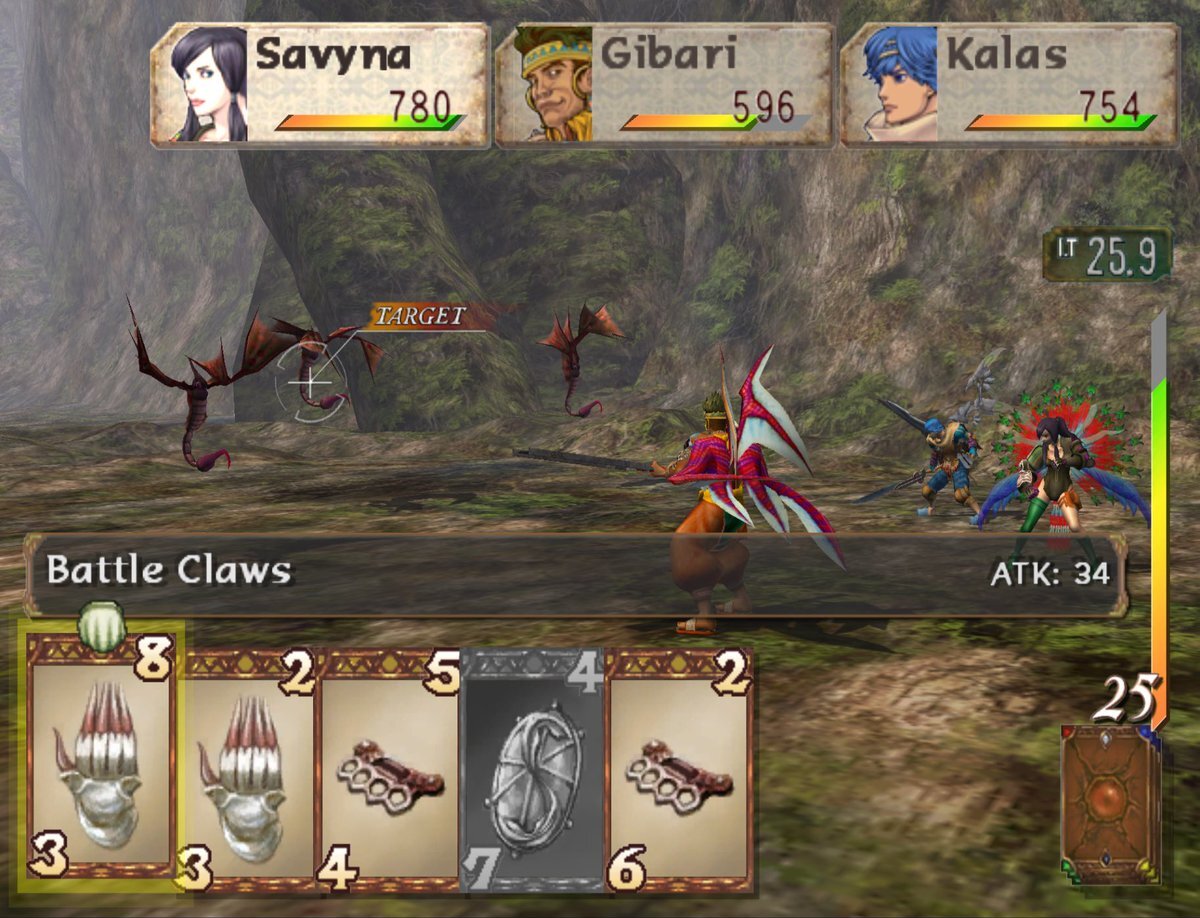
Savyna, as mentioned a while back, is a brawler. Her weapons are claws, iron knuckles, etc, she requires being a bit faster than the rest of the cast. Her outfit is also Textbook Combat Heels And Other Nonsense, which is... especially bizarre considering her characterization.
Lia
@liareplaysbk
· 09:38 PM · Oct 27, 2020
Permalink

Either way, we climb the tree, murdering everything along the way because they drop decent gear, and locate Mayfee, cornered on a platform by an angry floating shrimp.
Lia
@liareplaysbk
· 09:47 PM · Oct 27, 2020
Permalink



Get there, murder the shrimp, get confirmation that Mayfee’s there to get a flower to bloom. She’s not exactly the sharpest tool in the shed, especially compared to the obnoxiously smart kids we’ve met so far.
Lia
@liareplaysbk
· 09:49 PM · Oct 27, 2020
Permalink



This bit’s interesting. By now we’ve only seen Savyna as super-strong and confident, if mysterious and SuspiciousTM, but this suggests there might be some baggage somewhere. (Also pretty strong Mom Energy)
Lia
@liareplaysbk
· 09:50 PM · Oct 27, 2020
Permalink

We take her with us instead of dropping her off back at camp, because we’ll need her Keeper powers to open the door.
Lia
@liareplaysbk
· 10:32 PM · Oct 27, 2020
Permalink



I thought we’d established that breaking seals IS A BAD IDEA. Via the power of glowing spirographs and green butterflies, the door is now unlocked. Unlike Mayfee I’m pretty sure about what awaits inside: pendant laser, ominous doomtalk from a weird creature, boss battle.
Lia
@liareplaysbk
· 10:39 PM · Oct 27, 2020
Permalink
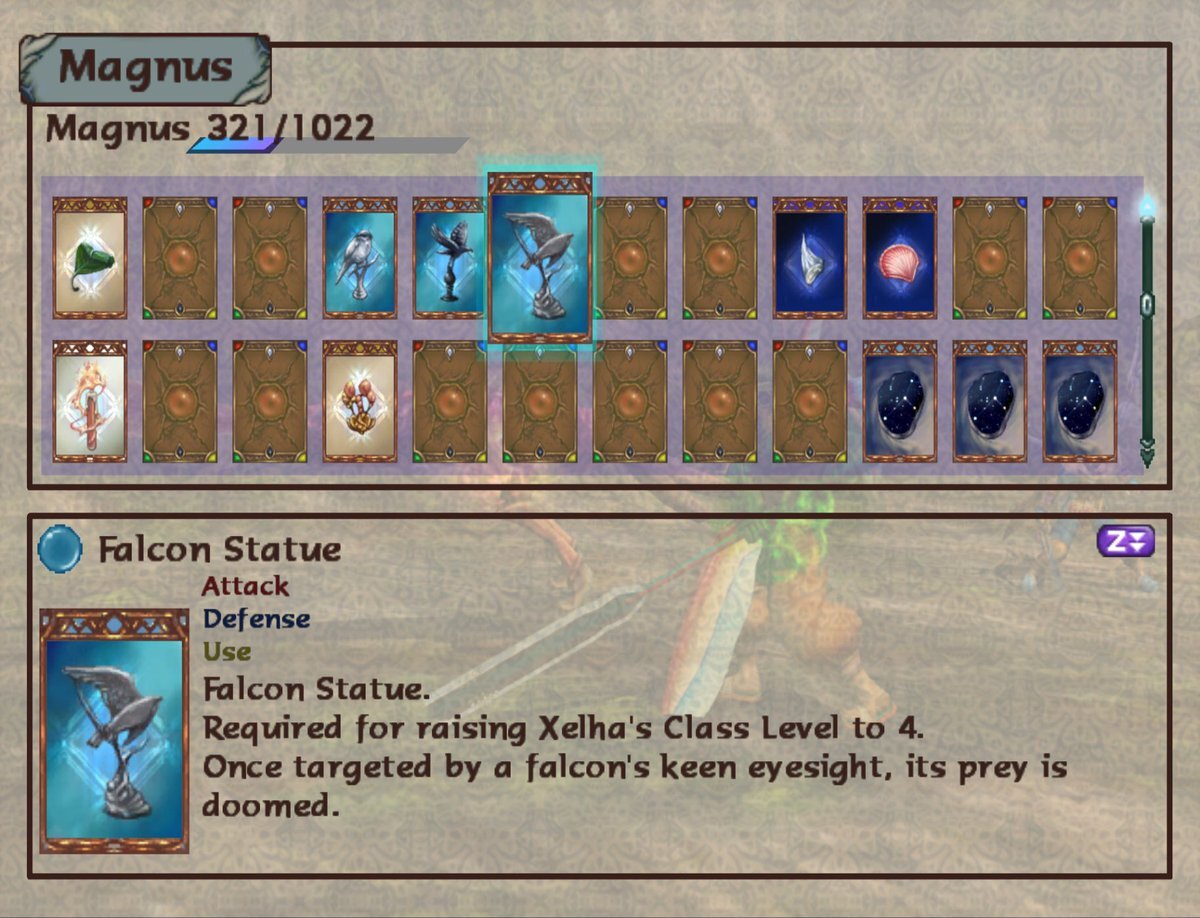
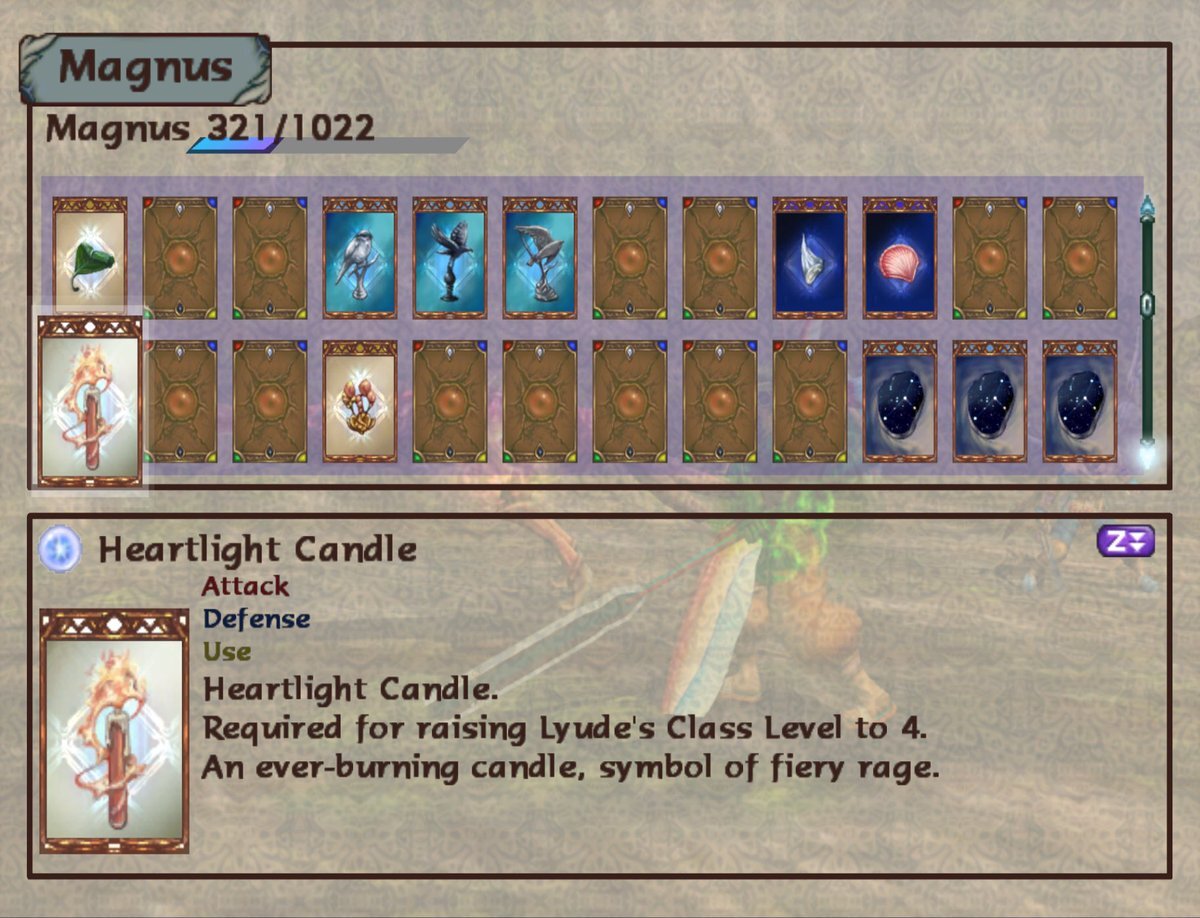
The Class Up items are supposed to be things of great importance to the characters. But for most of them they end up themed without much detail, e.g. Xelha gets bird statues, Gibari gets sea stuff. Lyude, however, gets... a “symbol of fiery rage”. Huh.
Lia
@liareplaysbk
· 10:43 PM · Oct 27, 2020
Permalink

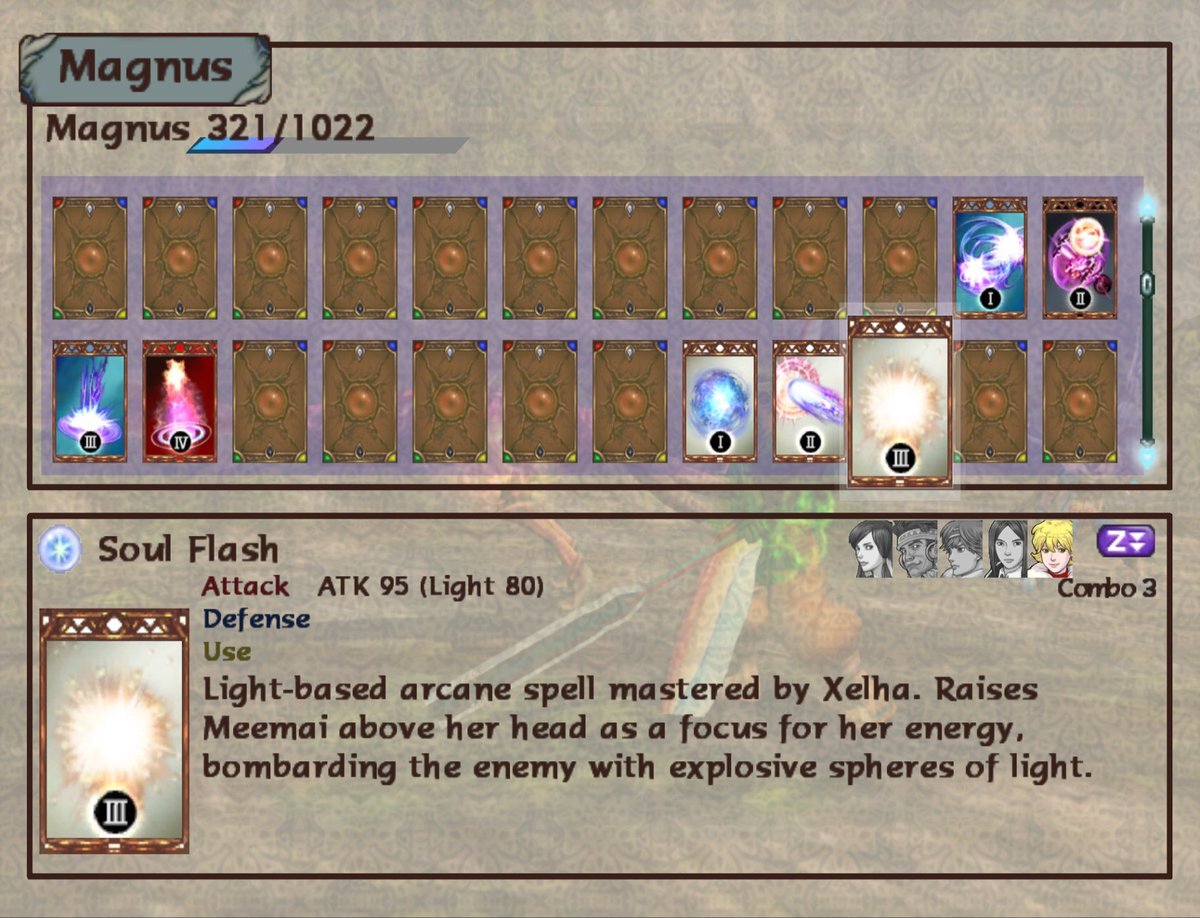
Similarly with the finishers, they’re deeply individual, but most of them don’t tell us that much beyond combat style and “aesthetics”. Unless we’re talking about Lyude, again, whose Sforzando is him “giving in to his rage, usually kept in check by rationale”.